Role Mining
Automated Role Engineering or 'Role Mining' is an important practical problem in information security: automatically migrating an existing access control infrastructure to Role-Based Access Control (RBAC).
What is RBAC?
RBAC is an approach for specifying user privileges for carrying out operations on system objects: Roles group together system privileges and users are assigned to roles, thereby granting them the associated privileges (see toy example below).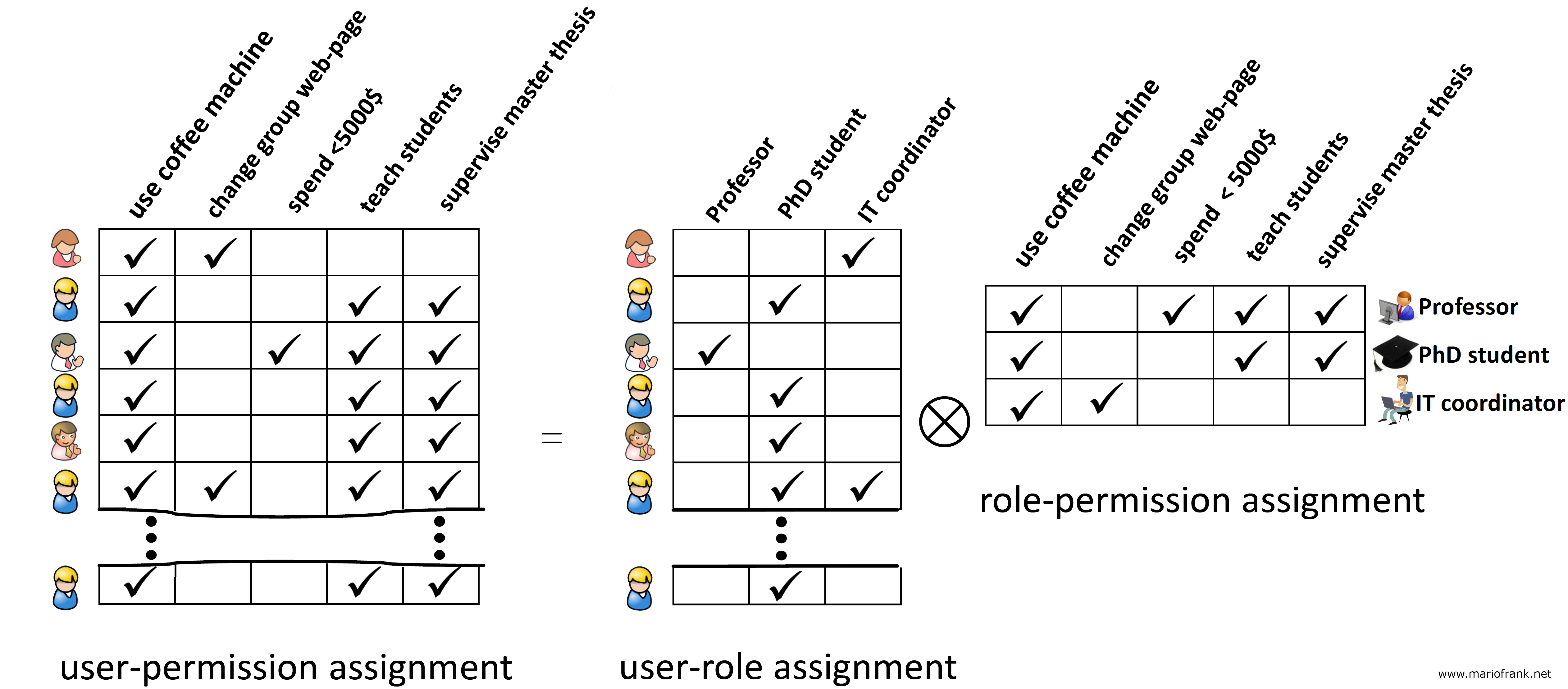
Although RBAC is conceptually simple, it is very difficult to configure RBAC systems in practice within large enterprises, i.e., to assign users and permissions to roles. This complexity leads to both high security administration costs and security weaknesses due to improperly implemented and administered security policies. To tackle these problems, we are working on data mining techniques for both configuring RBAC systems and for assessing configurations.
What is role mining?
Role mining is the problem of automatically finding a set of roles and the assignment of users to roles given a direct user-permission assignment. In the example depicted above, the role mining problem is: find the right side of the equation given the left side. More technically, role mining must find a Boolean factorization of a Boolean matrix, or a clustering of a set of Boolean vectors. In the above example both sides equal each other. In most real-world scenarios, small deviations are acceptable or even desired as, usually, the input data contains some erroneous user-permission assignments.From the machine learning perspective, role mining is interesting
i) because of the highly non-linear factorization of the input matrix and
ii) because objects can belong to more than one cluster at the same time.
We worked on a paper describing and defining the role mining problem ([5]). Our most recent journal publication [1] gives the most complete description of our approach to role mining.
Role mining algorithms
We first approached the role mining problem by bi-clustering [3] of the input matrix. This method works quite well but it has the drawback that each user only gets a single role. To overcome this limitation, we developed "Multi-Assignment Clustering" [2], a probabilistic model for clustering Boolean data in a way that objects can belong to multiple clusters. This method can be extended to also include business features of the users [4] such as, for instance, the business unit or the location. In this way, the inferred RBAC roles are intuitive to humans as they resemble business roles of the enterprise.In [6][7][8], we investigate model selection problems that arise in the context of role mining and other unsupervised learning problems.
Relevant publications:
-
Mario Frank, Joachim M. Buhmann, David Basin
"Role Mining with Probabilistic Models". In ACM Transactions on Information and System Security (Vol. 15, No. 4) , pages 1-28, ACM 2013
[ abstract | bib | pdf | doi ]
-
Mario Frank, Andreas P. Streich, David Basin and Joachim M. Buhmann.
"Multi-Assignment Clustering for Boolean Data"
In Journal of Machine Learning Research, 13(Feb): pages 459-489, 2012. .
[ bib | pdf | abstract | video & slides from ICML | code ]
-
Mario Frank, David Basin and Joachim M. Buhmann.
"A Class of Probabilistic Models for Role Engineering".
In CCS 2008: Proceedings of the 15th ACM conference on Computer and Communications Security, pages 299-310, ACM 2008.
[ bib | pdf | doi | abstract ]
-
Mario Frank, Andreas P. Streich, David Basin and Joachim M. Buhmann.
"A Probabilistic Approach to Hybrid Role Mining".
In CCS 2009: 16th ACM conference on Computer and Communications Security, pages 101-111, ACM 2009.
[ bib | pdf | doi | abstract ]
-
Mario Frank, Joachim M. Buhmann and David Basin
"On the Definition of Role Mining".
In SACMAT 2010: 15th ACM Symposium on Access Control Models and Technologies, pages 35-44, ACM 2010
[ slides | bib | pdf | doi | abstract ]
-
Mario Frank, Morteza Haghir Chehreghani and Joachim M. Buhmann
"The Minimum Transfer Cost Principle for Model-Order Selection".
ECML PKDD 2011: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases
[ bib | pdf | abstract | doi ]
-
Mario Frank and Joachim M. Buhmann
"Selecting the rank of truncated SVD by Maximum Approximation Capacity".
ISIT 2011: IEEE International Symposium on Information Theory
[ bib | pdf @ arXiv | abstract ]
-
Joachim M. Buhmann, Morteza Haghir Chehreghani, Mario Frank and Andreas P. Streich
"Information Theoretic Model Selection for Pattern Analysis".
in JMLR Workshop and Conference Proceedings 7, 1-8: ICML 2011 Workshop on Unsupervised and Transfer Learning
[ bib | pdf | slides | abstract ]
-
Mario Frank and Ian Molloy
"Tutorial on Role Mining".
At CCS 2010: 17th ACM conference on Computer and Communications Security, ACM 2010.
[ slides ]